
단일 문서단위가 아닌 문서유형의 등록/관리로 종속성을 탈피하고, 관리자가 설정한 정확도 기준에 미달하는 영역만
재 검증이 가능하도록 하여 데이터를 추출하고 이해하여 정형화 시키는 프로세스 자동화를 추구합니다.

비정형 상태의
이미지 및 전자문서

Text recognition

분류 > 이해 > 분석

정형화된 데이터로
변환
TwinReader API와 연계하여 개발된 고객사 UI로 이미지가 입력되면
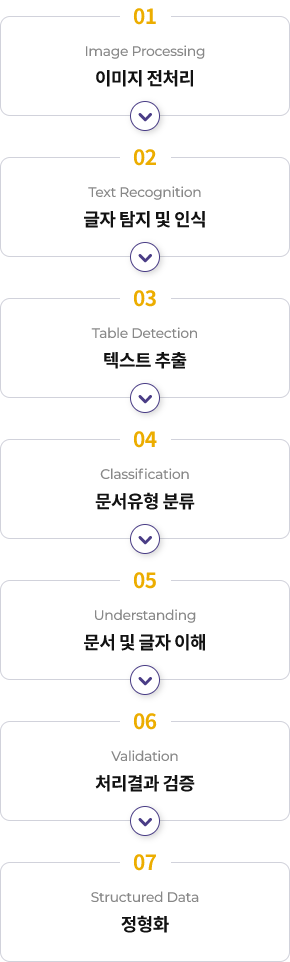
이미지 전 처리, 정보 추출 및 인식 정확도 검증절차를 거쳐 활용가능한 데이터로 변환됩니다.

서비스 관리
H/W 모니터링
API
Custom Models
Field Schema (Define extraction targets)
User Defined Plugin
테이블 내 이미지 처리
텍스트 요약 및 인식결과 보정
100%에 가까운 문서 자동화 추구

정확한 인식과 이해를 위한
위치 탐색 및 표 인식 텍스트 속성 인식 문서 유형 별 선택적 처리방식 제공사용자 편의를 위한
Extraction Engine & Multimodal Model 문서유형 분류 문서유형 별 인식모델제공 Workbench 운영 모니터링 지원최고의 성능을 위한
인식결과에 대한 신뢰도 검증 인식결과 보정 다른 시스템과의 결합사용
금융
상품계약서 / 서비스신청서 / 금융서식/ 고객관리문서/ 보고서

의료
의료비영수증/ 개인건강정보 문서

서비스
근로, 임대계약서/ 약관 및 법률조항/ 사용설명서

영업/재무
거래계약관리 / 재무제표/ 인보이스/ 영수증 및 결제관리/ 구매요청서 /견적 및 계약관/ 업체관리문서/ 자산관리문서

인사
기안, 보고서 관리 / 근태관리/ 복리후생관리/ 임직원 정보관리/ 정보인식 및 마스킹

제조/물류
제조 라벨링 검수/ 장비 매뉴얼/ 수요공급계획/ 생산정보정리/ 가격 및 재고관리/ 작업일정관리/ 프로세스 스케줄링/ 통관서류처리
A 생명 보험금 청구서 인식 및 자동화
연간 750만장에 이르는 전체 보험금청구서
처리 업무 자동화 진행 중
보험금 청구서 인식 정확도
도입 5년간 비용절감 효과
50억원B신용평가사 기업평가자료 전산화
기업고객 별로 각기 다른 양식과 정보를
표준화 하여, 항목별로 전산화
이미지 당 평균 처리속도
2.6초평균 인식 정확도
97.2% 이상C사 보험금 청구서 인식 및 자동화
시간 당 이미지 처리
4천건 이상문서 분류 성공률
95% 이상
